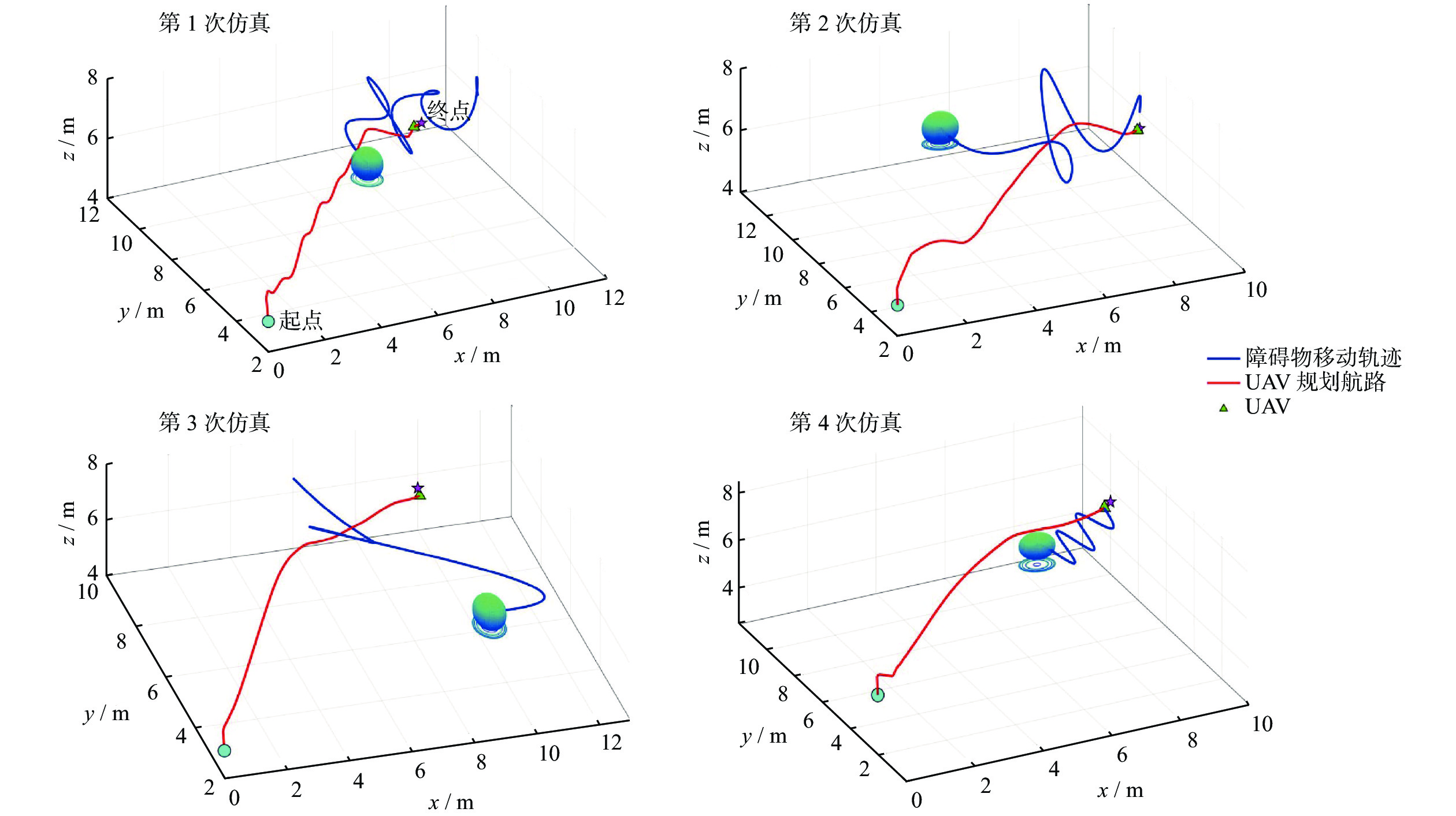
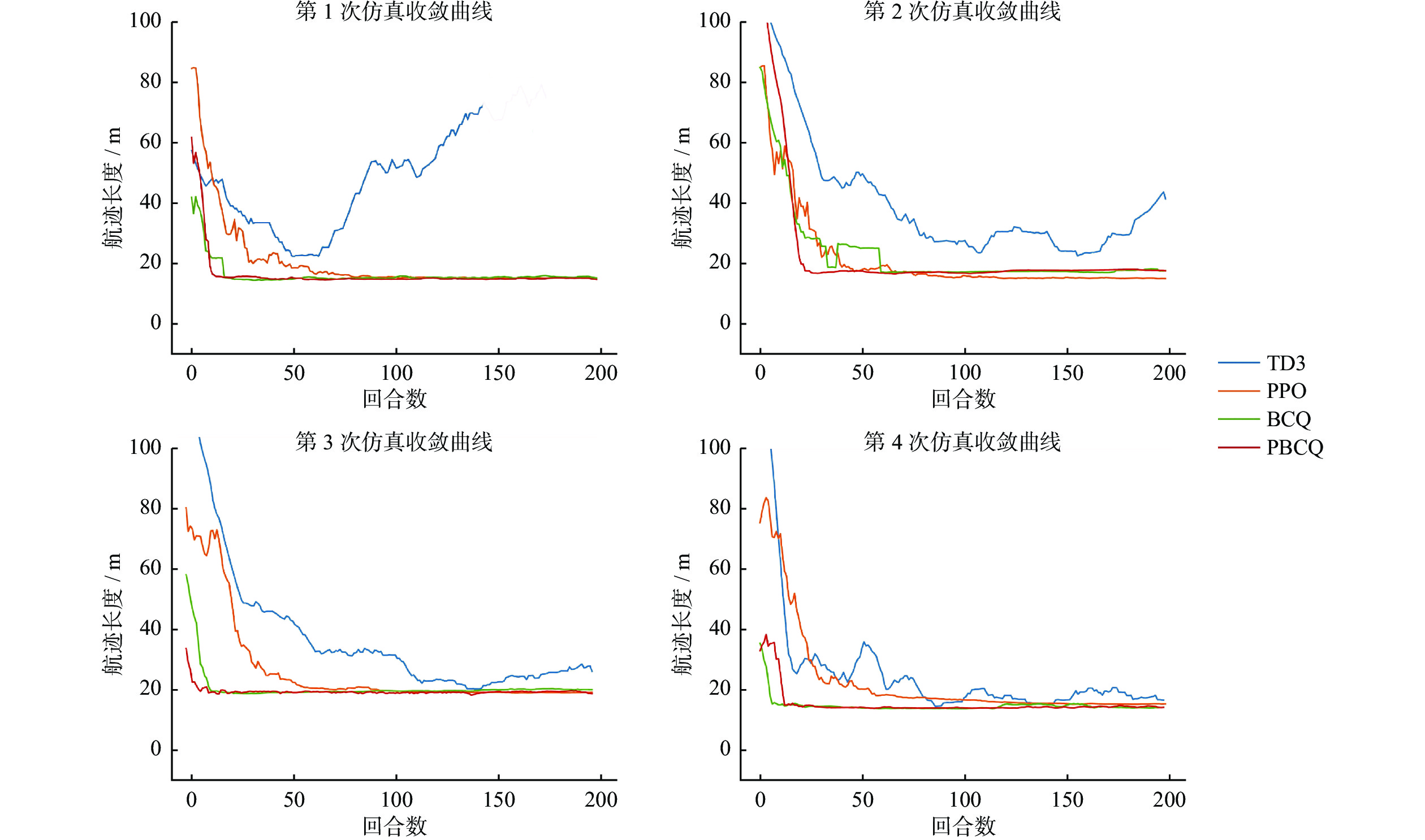
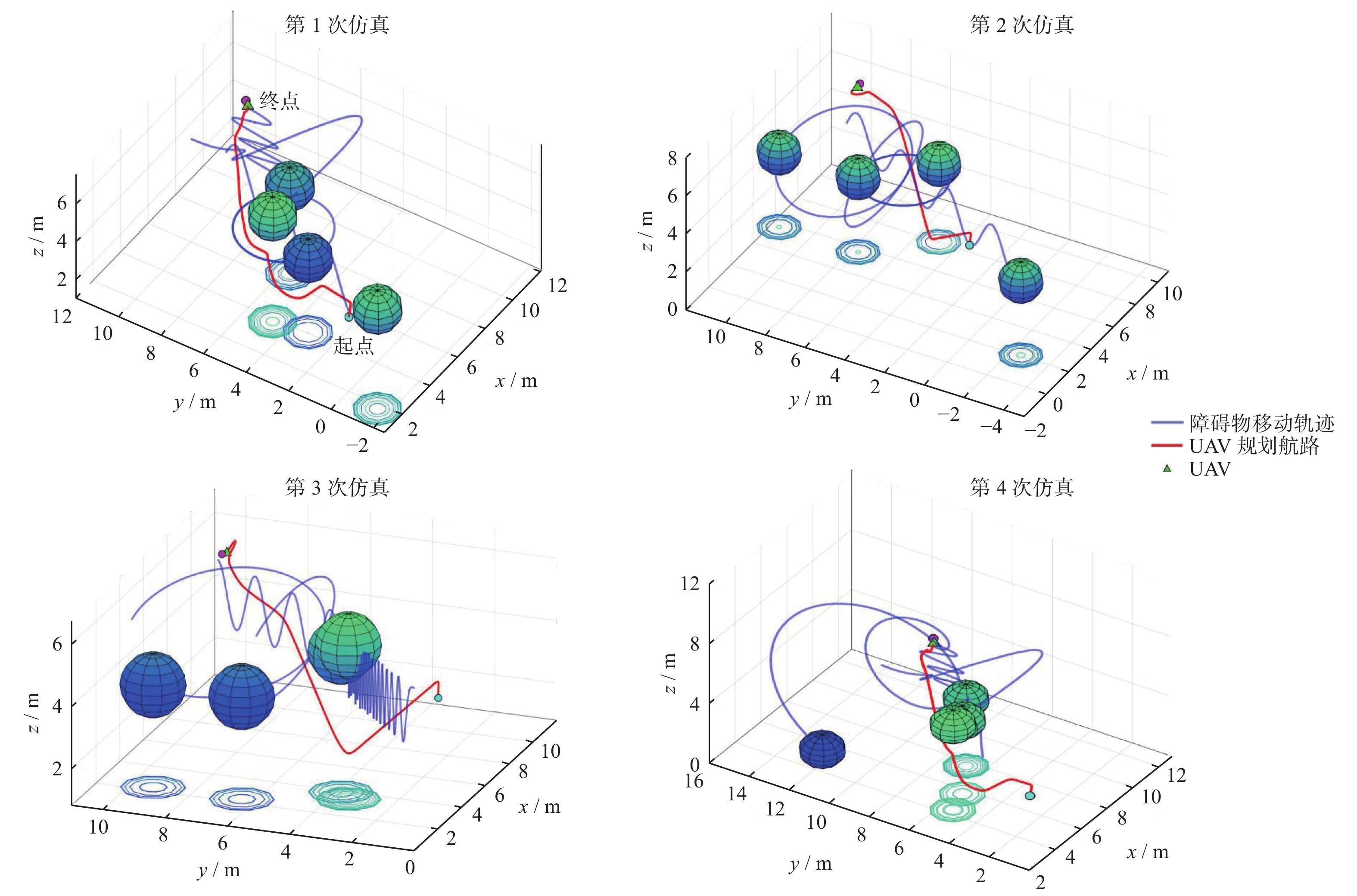
| Citation: | GE Qixing, ZHANG Wei, XIE Guiliang, HU Zhi. Offline reinforcement learning dynamic obstacles avoidance navigation algorithm[J]. Journal of Shanghai University of Engineering Science, 2024, 38(3): 313-320. doi: 10.12299/jsues.23-0227

|
| [1] |
NEX F, REMONDINO F. UAV for 3D mapping applications: a review[J] . Applied Geomatics,2014,6(1):1 − 15. doi: 10.1007/s12518-013-0120-x
|
| [2] |
RADOGLOU-GRAMMATIKIS P, SARIGIANNIDISP, LAGKAS T, et al. A compilation of UAV applications for precision agriculture[J] . Computer Networks,2020,172:107148. doi: 10.1016/j.comnet.2020.107148
|
| [3] |
ALZAHRANI B, OUBBATI O S, BARNAWI A, et al. UAV assistance paradigm: State-of-the-art in applications and challenges[J] . Journal of Network and Computer Applications,2020,166:102706. doi: 10.1016/j.jnca.2020.102706
|
| [4] |
多南讯, 吕强, 林辉灿, 等. 迈进高维连续空间: 深度强化学习在机器人领域中的应用[J] . 机器人,2019,41(2):276 − 288.
|
| [5] |
王怿, 祝小平, 周洲, 等. 3维动态环境下的无人机路径跟踪算法[J] . 机器人,2014,36(1):83 − 91.
|
| [6] |
陈海, 何开锋, 钱炜祺. 多无人机协同覆盖路径规划[J] . 航空学报,2016,37(3):928 − 935.
|
| [7] |
贾永楠, 田似营, 李擎. 无人机集群研究进展综述[J] . 航空学报,2020,41(S1):4 − 14.
|
| [8] |
赵晓, 王铮, 黄程侃, 等. 基于改进A算法的移动机器人路径规划[J] . 机器人,2018,40(6):903 − 910.
|
| [9] |
徐飞. 基于改进人工势场法的机器人避障及路径规划研究[J] . 计算机科学,2016,43(12):293 − 296. doi: 10.11896/j.issn.1002-137X.2016.12.054
|
| [10] |
GAMMELL J D, SRINIVASA S S, BARFOOT T D. Informed RRT*: Optimal sampling-based path planning focused via direct sampling of an admissible ellipsoidal heuristic[C] //Proceedings of 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems. Macao: IEEE, 2014: 2997 − 3004.
|
| [11] |
YANG H, QI J, MIAO Y, et al. A new robot navigation algorithm based on a double-layer ant algorithm and trajectory optimization[J] . IEEE Transactions on Industrial Electronics,2018,66(11):8557 − 8566.
|
| [12] |
FOX D, BURGARD W, THRUN S. The dynamic window approach to collision avoidance[J] . IEEE Robotics & Automation Magazine,1997,4(1):23 − 33.
|
| [13] |
CHEN Y F, LIU M, EVERETT M, et al. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning[C] //Proceedings of 2017 IEEE international conference on robotics and automation (ICRA). Singapore: IEEE, 2017: 285 − 292
|
| [14] |
EVERETT M, CHEN Y F, HOW J P. Motion planning among dynamic, decision-making agents with deep reinforcement learning[C] //Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE, 2018: 3052 − 3059.
|
| [15] |
FIORINI P, SHILLER Z. Motion planning in dynamic environments using velocity obstacles[J] . The International Journal of Robotics Research,1998,17(7):760 − 772. doi: 10.1177/027836499801700706
|
| [16] |
VAN DEN BERG J, LIN M, MANOCHA D. Reciprocal velocity obstacles for real-time multi-agent navigation[C] //Proceedings of 2008 IEEE international conference on robotics and automation. Pasadena: IEEE, 2008: 1928 − 1935.
|
| [17] |
ALONSO-MORA J, BREITENMOSER A, RUFLI M, et al. Optimal reciprocal collision avoidance for multiple non-holonomic robots[M] . Berlin: Springer, 2013: 203 − 216.
|
| [18] |
HAN R, CHEN S, WANG S, et al. Reinforcement learned distributed multi-robot navigation with reciprocal velocity obstacle shaped rewards[J] . IEEE Robotics and Automation Letters,2022,7(3):5896 − 5903. doi: 10.1109/LRA.2022.3161699
|
| [19] |
SUTTON R S, BARTO A G. Reinforcement learning: An introduction[M] . London: MIT press, 2018.
|
| [20] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL] . (2017−08−28)[2023−03−13] . https://arxiv.org/pdf/1707.06347.
|
| [21] |
FUJIMOTO S, VAN HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[EB/OL] . (2018−10−22)[2023−05−11] . https://arxiv.org/pdf/1802.09477.
|
| [22] |
FUJIMOTO S, MEGER D, PRECUP D. Off-policy deep reinforcement learning without exploration[EB/OL] . (2019−01−29)[2023−07−03] . https://www.researchgate.net/publication/329525481.
|
| [23] |
KUMAR A, FU J, SOH M, et al. Stabilizing off-policy Q-learning via bootstrapping error reduction[C] //Proceedings of the 33rd International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2019.
|
| [24] |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J] . Nature,2015,518:529 − 533. doi: 10.1038/nature14236
|
Figures(5) / Tables(2)
Copyright © Journal of Shanghai University of Engineering Science沪ICP备05052046号
Tel:86-21-67791000 Email:xuebao@sues.edu.cn
Address:333 Longteng Road, Shanghai, China China Pos:201620
Supported by:
Beijing Renhe Information Technology Co. Ltd



 DownLoad:
DownLoad: