

Self-training credit evaluation integrated classification model based on data editing
-
摘要: 针对信用数据不平衡及类标签数据难以获取的问题,提出一种基于数据剪辑的自训练信用评估集成分类模型。首先,采用合成少数类过采样法(SMOTE)在有标记样本上采样,以缓解数据不平衡性。其次,在少量带标签样本数据集上构建Stacking集成模型,并对无标记样本做“伪标记”,以获取类标签数据。最后,提出一种改进的双重加权半监督K近邻算法,并利用其剪辑伪标签数据和扩充训练集,直到模型收敛。使用UCI和Kaggle信用评估数据集进行仿真试验,结果表明,该模型具有更好的预测性能,更能有效识别少数类样本。
-
关键词:
- 信用评估 /
- 半监督学习 /
- Stacking集成策略 /
- 数据剪辑 /
- 自训练
Abstract: Aiming at the problems of unbalance of credit data and difficult acquisition of label data, a self-training credit evaluation integrated classification model based on data editing was proposed. Firstly, synthetic minority over-sampling technique (SMOTE) was used to sample labeled samples to alleviate data imbalance. Secondly, a Stacking integration model was constructed on a few labeled sample datasets and unlabeled samples were "falsified" to obtain label-like data. Finally, an improved semi-supervised double-weighted K-nearest neighbor algorithm was proposed, which was used to clip the pseudo-label data and expand the training set until the model converged. Simulation experiments of UCI and Kaggle credit evaluation dataset show that the model has better predictive performance and can identify a few types of samples more effectively. -

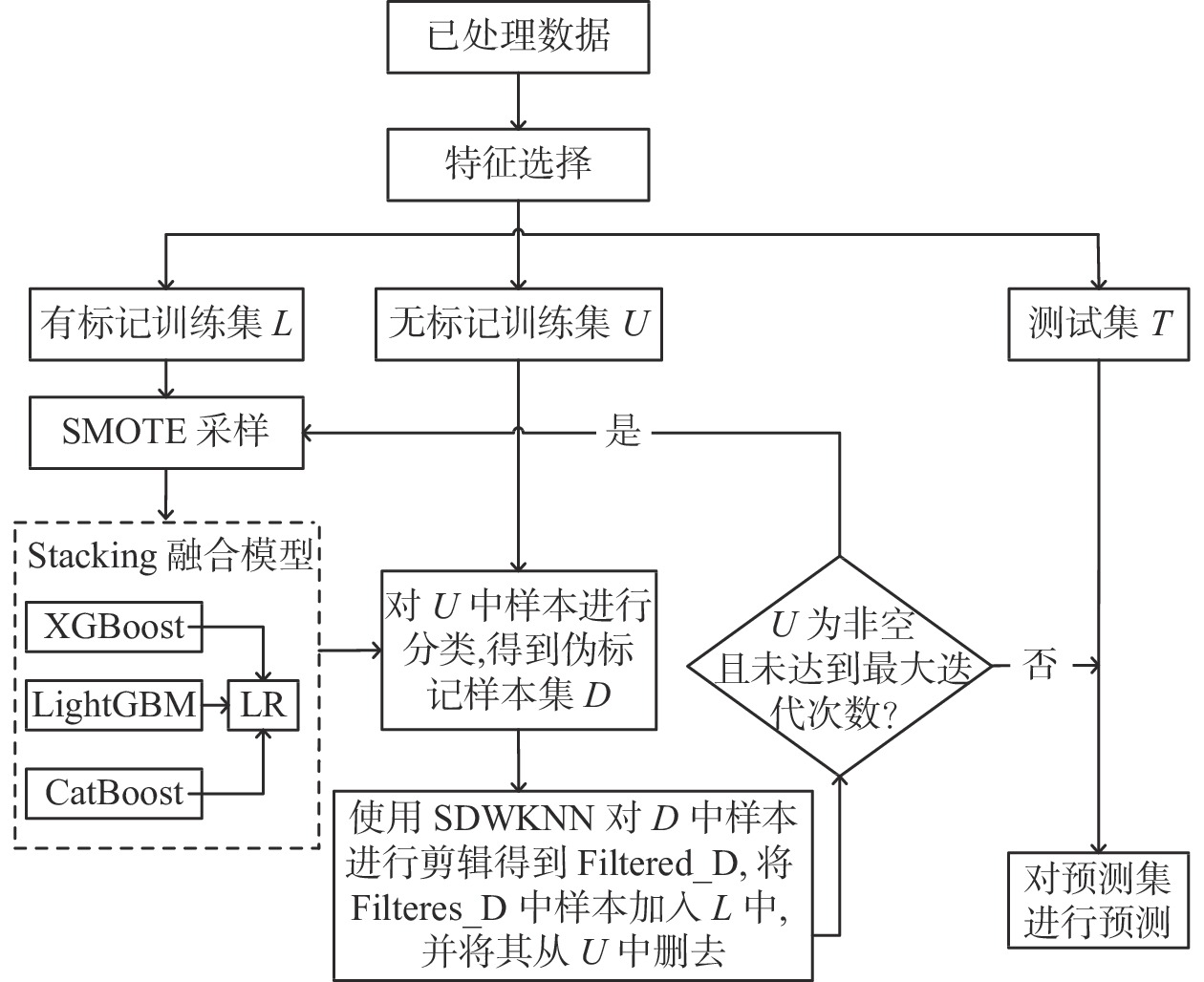
图 1 基于SDWKNN的自训练信用评估流程图
Figure 1. Self-training credit evaluation glow chart based on SDWKNN
表 1 数据集概况
Table 1. Data set overview
数据集 样本量 特征数 类别 正样占比/% Taiwanese 4618 92 2 4.8 Financial 3670 83 2 3.7  下载: 导出CSV
下载: 导出CSV
表 2 各个阶段参数设置
Table 2. Parameter Settings of each phase
数据集 SMOTE 特征选择 p SDWKNN Taiwanese (0.2, 4) 40 10 (4, 6) Financial (0.3, 3) 40 10 (4, 6)
下载: 导出CSV
表 4 各个模型G值对比
Table 4. Comparisons of G values of each model
编号 Taiwanese数据集 Financial数据集 3:2 1:1 1:2 1:3 1:4 均值 3:2 1:1 1:2 1:3 1:4 均值 1 0.699 0.682 0.632 0.620 0.602 0.647 0.518 0.520 0.487 0.522 0.487 0.507 2 0.664 0.696 0.671 0.629 0.609 0.654 0.491 0.480 0.519 0.499 0.459 0.490 3 0.683 0.669 0.670 0.626 0.626 0.655 0.503 0.483 0.436 0.492 0.468 0.476 4 0.664 0.680 0.680 0.641 0.658 0.665 0.708 0.713 0.707 0.707 0.707 0.708 5 0.679 0.645 0.658 0.670 0.659 0.662 0.537 0.474 0.534 0.559 0.542 0.529 6 0.706 0.678 0.709 0.697 0.688 0.696 0.707 0.713 0.718 0.718 0.718 0.715 7 0.712 0.730 0.753 0.736 0.748 0.736 0.707 0.718 0.718 0.717 0.718 0.715 8 0.726 0.724 0.759 0.748 0.756 0.743 0.707 0.718 0.718 0.718 0.718 0.716
下载: 导出CSV
表 5 各个模型F值对比
Table 5. Comparisons of F values of each model
编号 Taiwanese数据集 Financial数据集 3:2 1:1 1:2 1:3 1:4 均值 3:2 1:1 1:2 1:3 1:4 均值 1 0.577 0.554 0.489 0.469 0.463 0.510 0.355 0.364 0.322 0.357 0.309 0.341 2 0.552 0.589 0.571 0.505 0.491 0.542 0.330 0.317 0.349 0.334 0.291 0.324 3 0.583 0.564 0.575 0.512 0.517 0.550 0.351 0.329 0.269 0.342 0.308 0.320 4 0.552 0.568 0.582 0.526 0.560 0.558 0.388 0.393 0.386 0.385 0.384 0.387 5 0.561 0.508 0.524 0.540 0.536 0.534 0.295 0.233 0.289 0.308 0.303 0.286 6 0.590 0.556 0.563 0.542 0.532 0.557 0.386 0.391 0.395 0.396 0.396 0.393 7 0.574 0.588 0.585 0.536 0.562 0.569 0.386 0.397 0.395 0.391 0.394 0.393 8 0.606 0.578 0.593 0.546 0.562 0.577 0.386 0.397 0.394 0.394 0.394 0.393
下载: 导出CSV
-
[1] 高俊光, 刘旭, 朱辰辰. 小微企业信用评估的数据挖掘方法综述[J] . 金融理论与实践,2015(10):98 − 101. doi: 10.3969/j.issn.1003-4625.2015.10.019 [2] 周永圣, 崔佳丽, 周琳云, 等. 基于改进的随机森林模型的个人信用风险评估研究[J] . 征信,2020,38(1):28 − 32. doi: 10.3969/j.issn.1674-747X.2020.01.006 [3] 张田华, 罗康洋. 基于集成学习的上市公司高送转预测实证研究[J] . 计算机工程与应用,2022,58(10):255 − 262. doi: 10.3778/j.issn.1002-8331.2011-0224 [4] 罗康洋, 王国强. 基于改进的MRMR算法和代价敏感分类的财务预警研究[J] . 统计与信息论坛,2020,35(3):77 − 85. doi: 10.3969/j.issn.1007-3116.2020.03.011 [5] 张涛, 汪御寒, 李凯, 等. 基于样本依赖代价矩阵的小微企业信用评估方法[J] . 同济大学学报(自然科学版),2020,48(1):149 − 158. doi: 10.11908/j.issn.0253-374x.19017 [6] YAROWSKY D. Unsupervised word sense disambiguation rivaling supervised methods[C]// Proceedings of the 33rd annual meeting on Association for Computational Linguistics. Cambridge: Association for Computational Linguistics, 1995: 189−196. [7] ZHOU Z H. When semi-supervised learning meets ensemble learning[C]// Proceedings of the 8th International Workshop on Multiple Classifier Systems. Reykjavik: Springer, 2009: 529−538. [8] HADY M F A, SCHWENKER F. Co-training by committee: A generalized framework for semi-supervised learning with committees[J] . International Journal of Software and Informatics,2008,2(2):95 − 124. [9] 黎春, 周振宇. 信用评分模型中拒绝推断问题研究: 基于半监督协同训练法的改进[J] . 统计研究,2019,36(9):82 − 92. [10] WANG G. D-self-smote: New method for customer credit risk prediction based on self-training and smote[J] . Icic Express Letters Part B Applications An International Journal of Research & Surveys,2018,9(3):241 − 246. [11] 肖进, 李思涵, 贺小舟, 等. 代价敏感的客户流失预测半监督集成模型研究[J] . 系统工程理论与实践,2021,41(1):188 − 199. doi: 10.12011/SETP2019-2879 [12] 张天翼, 丁立新. 一种基于SMOTE的不平衡数据集重采样方法[J] . 计算机应用与软件,2021,38(9):273 − 279. doi: 10.3969/j.issn.1000-386x.2021.09.043 [13] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: Synthetic minority over-sampling technique[J] . Journal of Artificial Intelligence Research,2002,16:321 − 357. doi: 10.1613/jair.953 [14] 岳鹏, 侯凌燕, 杨大利, 等. 基于XGBoost特征选择的疾病诊断XLC-Stacking方法[J] . 计算机工程与应用,2020,56(17):136 − 141. [15] WOLPERT D H. Stacked generalization[J] . Neural Networks,1992,5(2):241 − 259. doi: 10.1016/S0893-6080(05)80023-1 [16] 陆万荣, 许江淳, 李玉惠. 面向Stacking集成的改进分类算法及其应用[J] . 计算机应用与软件,2022,39(2):281 − 286. doi: 10.3969/j.issn.1000-386x.2022.02.045 [17] 韩嵩, 韩秋弘. 半监督学习研究的述评[J] . 计算机工程与应用,2020,56(6):19 − 27. doi: 10.3778/j.issn.1002-8331.1911-0083 [18] 龚旭. 半监督协同训练算法中样本去噪的研究[D]. 重庆: 重庆师范大学, 2021. [19] 潘用科, 贺紫平, 夏克文, 等. 改进的协同训练半监督SVM在油层识别中的应用[J] . 郑州大学学报(工学版),2022,43(1):14 − 19. doi: 10.13705/j.issn.1671-6833.2022.01.001 [20] 陈日新, 朱明旱. 半监督k近邻分类方法[J] . 中国图象图形学报,2013,18(2):195 − 200. doi: 10.11834/jig.20130210 [21] 陈振洲, 李磊, 姚正安. 基于SVM的特征加权KNN算法[J] . 中山大学学报(自然科学版),2005(1):17 − 20. doi: 10.3321/j.issn:0529-6579.2005.01.005 [22] UCI Machine Learning Repository. Taiwanese Bankruptcy Prediction[EB/OL]. (2020-06-27)[2022-12-23]. https://archive.ics.uci.edu/ml/datasets/Taiwanese+Bankruptcy+Prediction.html. [23] Kaggle. Financial distress Preduction[EB/OL]. (2017-12-15)[2022-12-23]. https://www.kaggle.com/datasets/shebrahimi/financial-distress.html. -
 下载:
下载:
 点击查看大图
点击查看大图
计量
- 文章访问数: 803
- HTML全文浏览量: 475
- PDF下载量: 122
- 被引次数: 0
