

BiLSTM_Attention text classification method based on pre-trained model ERNIE3.0
-
摘要: 为提高文本分类模型的准确率,改善传统词向量模型在语法、语义及深层次信息表现上的不足,提出一种基于ERNIE3.0预训练模型的 BiLSTM_Attention的文本分类模型。首先,使用ERNIE3.0模型对文本数据集编码,生成具有丰富语义信息的词向量。然后,通过BiLSTM层和Attention层提取文本特征。最后,通过Softmax层对输出的词向量进行分类。在THUCNews数据集上进行分类实验,对比不同模型的准确率及F1指标值。结果表明,ERNIE3.0_BiLSTM_Attention模型具有更好的分类效果。Abstract: To enhance the accuracy of text classification models and address the deficiencies of traditional word vector models in syntax, semantics, and deep-level information representation, a text classification model based on the ERNIE 3.0 pre-trained model with BiLSTM_Attention was proposed. First, the ERNIE 3.0 model was used to encode text dataset, generating word vectors with rich semantic information. Subsequently, text features were extracted through the BiLSTM layer and the Attention layer. Finally, the output word vectors were classified via the Softmax layer. Classification experiments conducted on the THUCNews dataset compared the accuracy and F1-score metrics across different models. The results show that the ERNIE 3.0_BiLSTM_Attention model achieves superior classification performance.
-
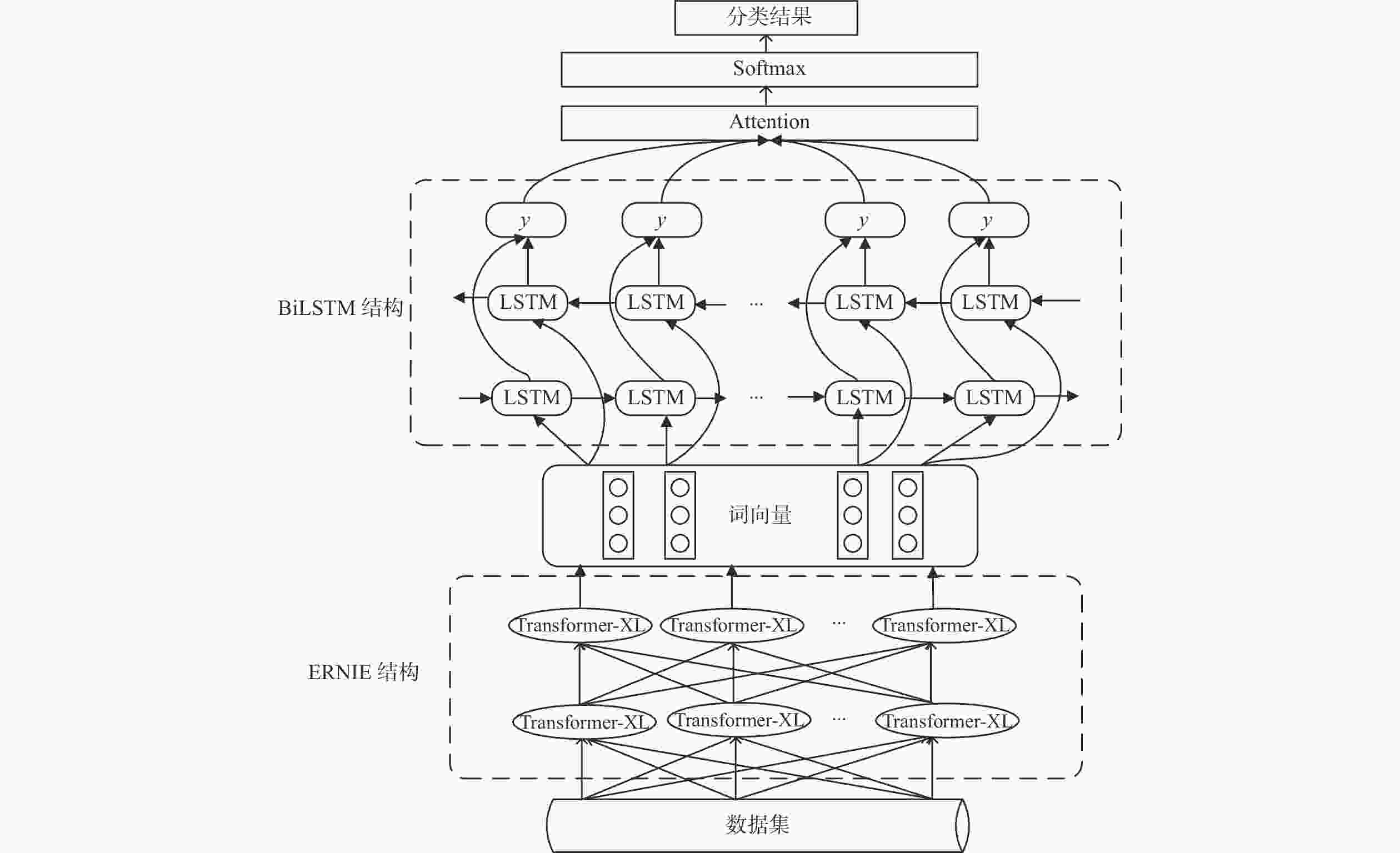
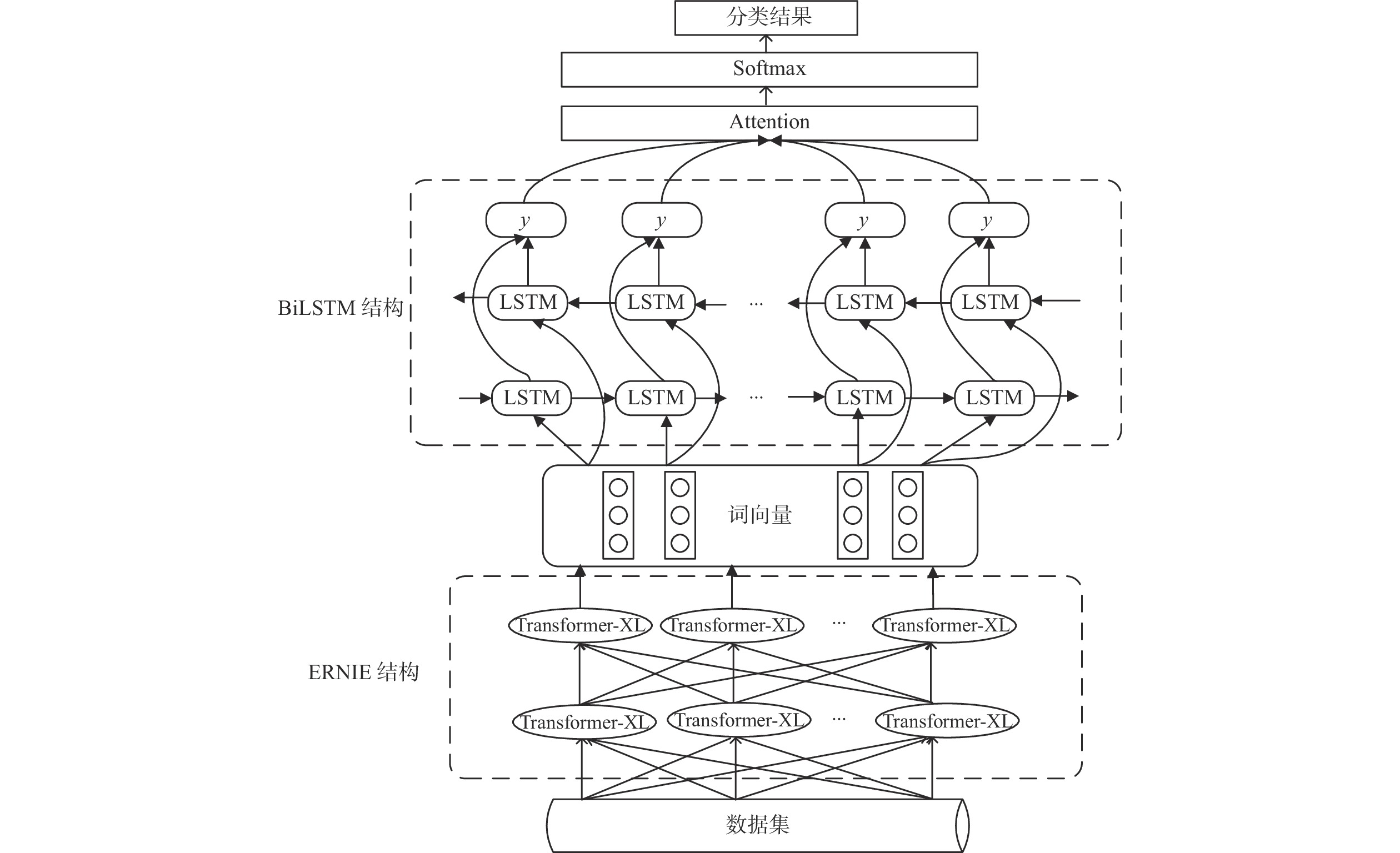
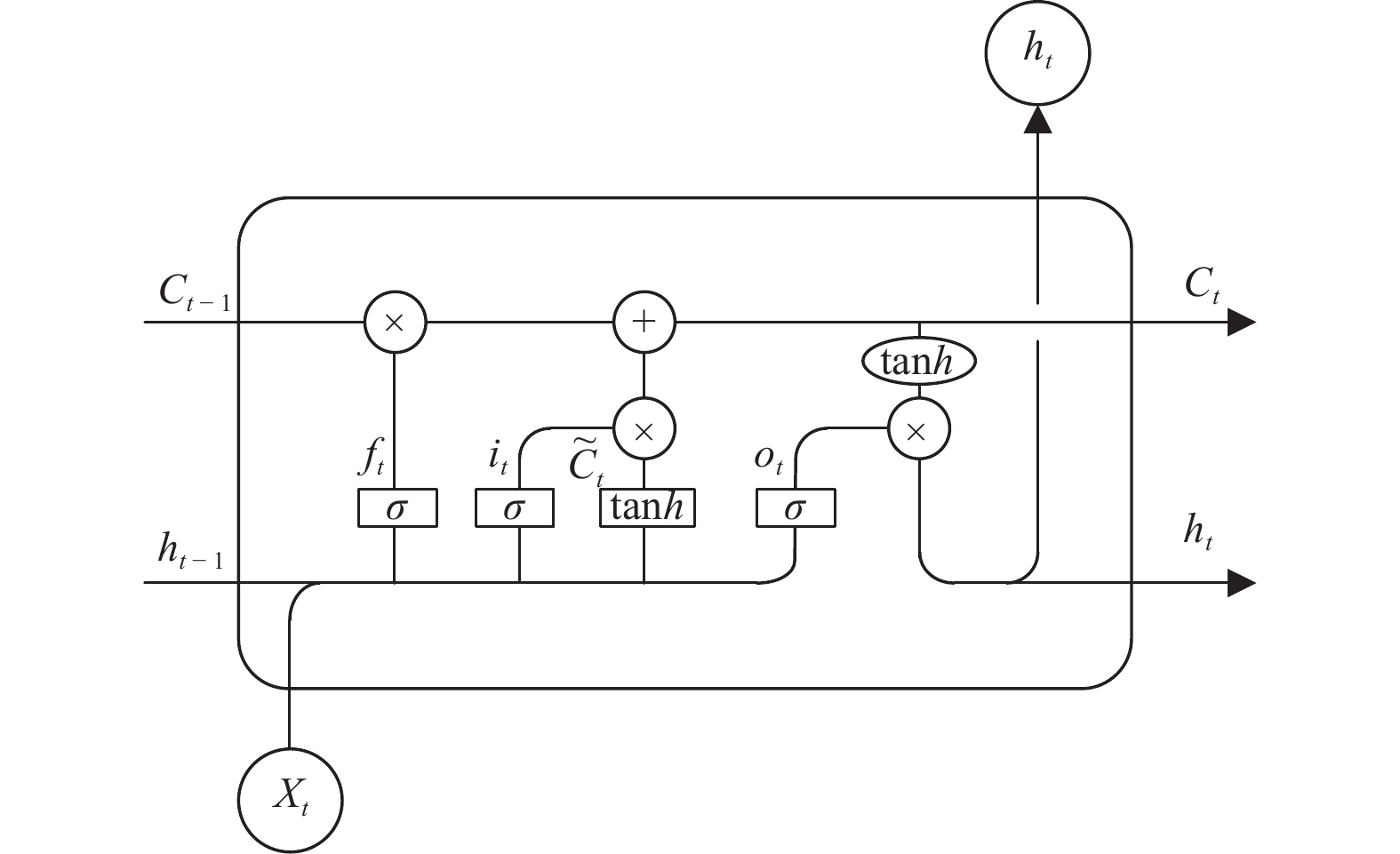
图 2 ERNIE3.0_BiLSTM_Attention模型结构图
Figure 2. Structure diagram of ERNIE3.0_BiLSTM_Attention model
表 1 模型参数设置
Table 1. Model parameter configuration
名称 参数值 Epoch 3 Batch_Size 128 learning rate 6e-5 dropout 0.1  下载: 导出CSV
下载: 导出CSV
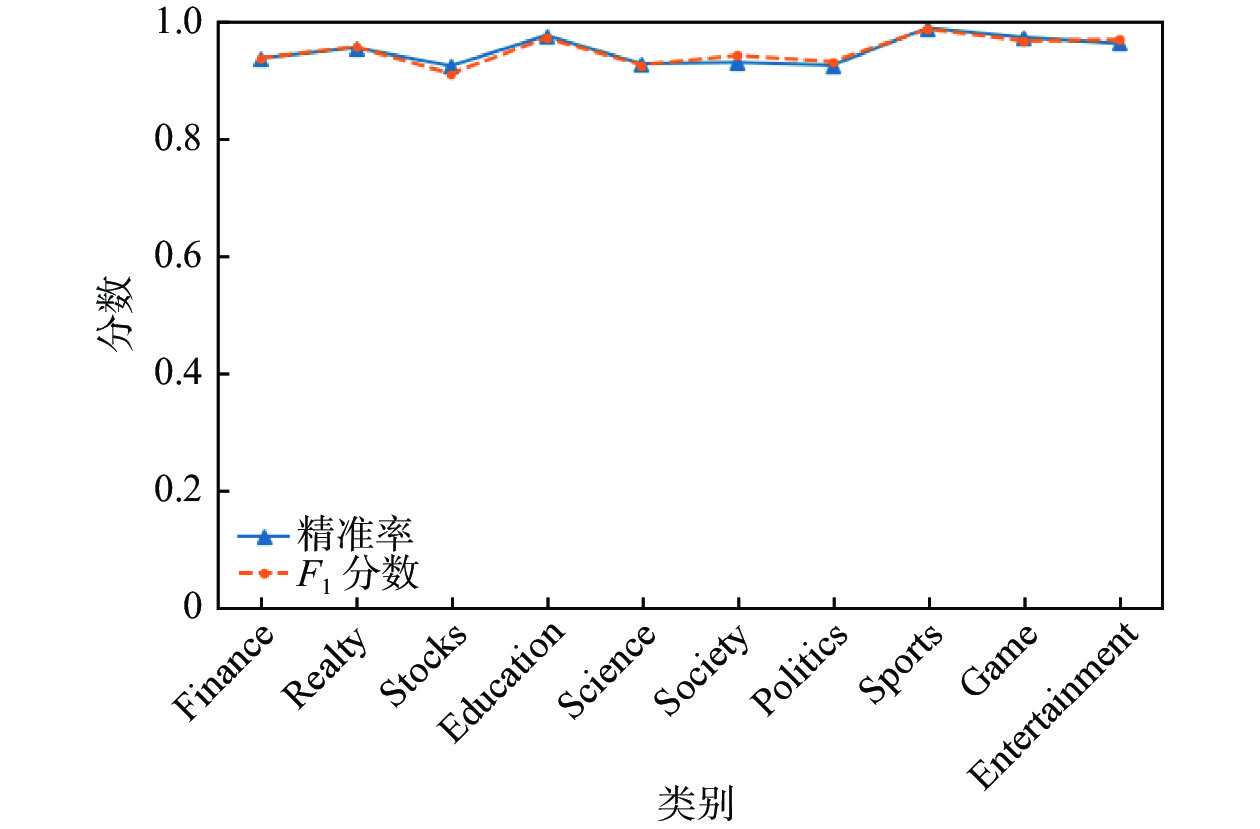
表 2 THUCNews数据集实验结果
Table 2. Experimental results on THUCNews dataset
类别 P R F1 Finance 0.9391 0.940 0.9395 Realty 0.9571 0.960 0.9586 Stocks 0.9259 0.900 0.9128 Education 0.9778 0.969 0.9734 Science 0.9297 0.926 0.9279 Society 0.9318 0.956 0.9437 Politics 0.9270 0.940 0.9335 Sports 0.9910 0.987 0.989 Game 0.9747 0.963 0.9688 Entertainment 0.9645 0.977 0.9707
下载: 导出CSV
表 3 不同模型结果对比
Table 3. Results comparison of different models
模型 准确率/% TextCNN 90.78 TextRCNN 91.31 FastText 91.80 Bert + BiLSTM + Attention 94.80 Robert + BiLSTM + Attention 90.90 ERNIE1.0 + BiLSTM + Attention 94.88 ERNIE3.0 + BiLSTM + Attention 95.18
下载: 导出CSV
表 4 消融实验结果对比
Table 4. Comparison of ablation experimental results
模型 准确率/% BiLSTM + Attention 90.86 ERNIE3.0 + BiLSTM 94.73 ERNIE3.0 + BiLSTM + Attention 95.18
下载: 导出CSV
-
[1] TONG S, KOLLER D. Support vector machine active learning with applications to text classification[J] . Journal of Machine Learning Research,2001(2):45 − 66. [2] TAN S. An effective refinement strategy for KNN text classifier[J] . Expert Systems with Applications,2006,30(2):290 − 298. doi: 10.1016/j.eswa.2005.07.019 [3] 李航. 统计学习方法[M] . 北京: 清华大学出版社, 2012: 47 − 53. [4] JONES K S. A statistical interpretation of term specificity and its application in retrieval[J] . Journal of Documentation,2004,60(5):493 − 502. doi: 10.1108/00220410410560573 [5] PENNINGTON J , SOCHER R , MANNING C . Glove: global vectors for word representation[C] //Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha: Association for Computational Linguistics, 2014: 1532–1543. [6] JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification[EB/OL] . (2016-08-09)[2023-05-16] . https://doi.org/10.48550/arXiv.1607.01759. [7] KIM Y . Convolutional neural networks for sentence classification[EB/OL] . (2014−09−03)[2023−05−16] . https://doi.org/10.48550/arXiv.1408.5882. [8] GRAVES A, SCHMIDHUBER J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J] . Neural Networks,2005,18(5):602 − 610. [9] 和志强, 杨建, 罗长玲. 基于BiLSTM神经网络的特征融合短文本分类算法[J] . 智能计算机与应用,2019,9(2):21 − 27. doi: 10.3969/j.issn.2095-2163.2019.02.005 [10] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C] //Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: Curran Associates Inc. , 2017: 6000 – 6010. [11] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C] //Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis: Association for Computational Linguistics, 2019: 4171 – 4186. [12] 张洋, 胡燕. 基于多通道深度学习网络的混合语言短文本情感分类方法[J] . 计算机应用研究,2021,38(1):69 − 74. [13] 张军, 邱龙龙. 一种基于BERT和池化操作的文本分类模型[J] . 计算机与现代化,2022(6):1 − 7. doi: 10.3969/j.issn.1006-2475.2022.06.001 [14] SUN Y, WANG S, FENG S, et al. Ernie 3.0: large-scale knowledge enhanced pre-training for language understanding and generation[EB/OL] . (2021−07−15)[2023−05−16] . https://doi.org/10.48550/arXiv.2107.02137. [15] 张欣, 翟正利, 姚路遥. 基于CNN和LSTM混合模型的中文新闻文本分类[J] . 计算机与数字工程,2023,51(7):1540 − 1543, 1573. doi: 10.3969/j.issn.1672-9722.2023.07.018 [16] 杨兴锐, 赵寿为, 张如学, 等. 结合自注意力和残差的BiLSTM_CNN文本分类模型[J] . 计算机工程与应用,2022,58(3):172 − 180. doi: 10.3778/j.issn.1002-8331.2104-0258 [17] 张小为, 邵剑飞. 基于改进的BERT-CNN模型的新闻文本分类研究[J] . 电视技术,2021,45(7):146 − 150. -
 下载:
下载:
 点击查看大图
点击查看大图
计量
- 文章访问数: 974
- HTML全文浏览量: 418
- PDF下载量: 45
- 被引次数: 0
